Structure Function Science Showcase#
[1]:
import tape
from tape import Ensemble
from tape.utils import ColumnMapper
from tape.analysis.structure_function.base_argument_container import StructureFunctionArgumentContainer
import eztao
import numpy as np
import matplotlib.pyplot as plt
Introduction#
Structure function is often used to quantify the fluctuations or variations in a signal as a function of spatial or temporal separation. It is a method to analyze and describe the statistical properties of fluctuations within a dataset. In this tutorial, we will show how to use and employ structure function calculation as written in TAPE.
First, before we get to the structure function calculations, we want to create the data with known temporal properties (and known structure function) so that we can verify our results. We will use the package EzTao, which enables us to create lightcurves with known variability. We will generate lightcurves with the process of damped random walk (represenatitive of typical AGN variability). Damped random walk differs from a standard random walk process by having an additional term that does
not allow the process to venture too far away from its mean.
These lightcurves created in this fashion fully described with two parameters - amplitude and decorrelation scale.
[2]:
from eztao.carma import DRW_term
from eztao.ts import gpSimRand
# amp is the amplitude of the process and tau is the decorrelation timescale
amp = 0.2
tau = 100
# Create the kernel
DRW_kernel = DRW_term(np.log(amp), np.log(tau))
# specify how many lightcurves and observational details
num_light_curves = 100
snr = 10
duration_in_days = 365 * 10
num_observations = 200
# Generate `num_light_curves` lightcurves
# t, y, yerr are np.ndarray with shape = (num_light_curves, num_observations)
t, y, err = gpSimRand(
carmaTerm=DRW_kernel, SNR=snr, duration=duration_in_days, N=num_observations, nLC=num_light_curves
)
# pick 10 lightcurves at random and plot (with small offset for clarity)
sel_10 = np.random.choice(len(t), size=10, replace=False)
plt.figure(dpi=150, figsize=(10, 5))
for i, j in enumerate(sel_10):
plt.errorbar(t[j], y[j] + i * 0.2, yerr=err[j], ls="", marker=".", ms=4, capsize=2)
plt.xlabel("time [unit]")
plt.ylabel("magnitude [unit]")
[2]:
Text(0, 0.5, 'magnitude [unit]')

We now calculate the structure function for these 10 lightcurves independently. This can be achieved by direct use of calc_sf2 function, which takes times of the measurements, values of the measurements and the errors. The default method for calculating structure functions is to compute the variance of all of the data pairs in the time bin and subtract the squared error of the measurements, i.e.,
where the sum is over all \(P\) measurements which are separate by a time lag \(\Delta t\), \(m\) are the values of measurements, and we are taking into account the measurement errors \(\sigma\) of the individual data points (See Press+ 1992, or Caplar+ 2017 Equation 1, or Kozlowski 2017 Equation 12).
[3]:
# We show here structure function for the same 10 lightcurves
plt.figure()
for i, j in enumerate(sel_10):
res_basic = tape.analysis.calc_sf2(t[j], y[j], err[j])
plt.plot(
res_basic["dt"],
res_basic["sf2"],
marker=".",
)
plt.yscale("log")
plt.xscale("log")
plt.title("Structure Function^2")
plt.xlabel("Time [time unit]")
plt.ylabel("SF^2 [magnitude unit^2]")
plt.show()

Working with Ensemble#
Even though all of the lightcurves were generated with the same underlying process, we see that there are differences, due to the stochastic nature of the process. The power of structure function calculation is that it can operate on multiple lightcurves at once, even if the lightcurves have different cadence of observations and different measurement uncertainties!
In order to show how this can be achieved, we will first put all of the 100 lightcurves generated in a TAPE ensemble.
[4]:
id_ens, t_ens, y_ens, yerr_ens, filter_ens = (
np.array([]),
np.array([]),
np.array([]),
np.array([]),
np.array([]),
)
for j in range(num_light_curves):
id_ens = np.append(id_ens, np.full(num_observations, j))
t_ens = np.append(t_ens, t[j])
y_ens = np.append(y_ens, y[j])
yerr_ens = np.append(yerr_ens, err[j])
filter_ens = np.append(filter_ens, np.full(num_observations, "r"))
[5]:
id_ens, t_ens, y_ens, yerr_ens, filter_ens = [], [], [], [], []
for j in range(num_light_curves):
id_ens.append(np.full(num_observations, j))
t_ens.append(t[j])
y_ens.append(y[j])
yerr_ens.append(err[j])
filter_ens.append(np.full(num_observations, "r"))
id_ens = np.array(id_ens)
t_ens = np.array(t_ens)
y_ens = np.array(y_ens)
yerr_ens = np.array(yerr_ens)
filter_ens = np.array(filter_ens)
[6]:
# First, we create all the columns that we will want to fill
# In addition to time, measurement and errors, this includes
# id for each lightcurve and information about the filter used
# For the purpose of this tutorial let's assume we are observing in `r` filter
id_ens, t_ens, y_ens, yerr_ens, filter_ens = [], [], [], [], []
for j in range(num_light_curves):
id_ens.append(np.full(num_observations, j))
t_ens.append(t[j])
y_ens.append(y[j])
yerr_ens.append(err[j])
filter_ens.append(np.full(num_observations, "r"))
id_ens = np.concatenate(id_ens)
t_ens = np.concatenate(t_ens)
y_ens = np.concatenate(y_ens)
yerr_ens = np.concatenate(yerr_ens)
filter_ens = np.concatenate(filter_ens)
# This line makes sure that ids are integers
id_ens = id_ens.astype(int)
# Create ColumnMapper object that will tell ensemble
# meaning of each column
manual_colmap = ColumnMapper().assign(
id_col="id_ens", time_col="t_ens", flux_col="y_ens", err_col="yerr_ens", band_col="filter_ens"
)
ens = Ensemble()
ens.from_source_dict(
{"id_ens": id_ens, "t_ens": t_ens, "y_ens": y_ens, "yerr_ens": yerr_ens, "filter_ens": filter_ens},
column_mapper=manual_colmap,
sorted=True,
)
[6]:
<tape.ensemble.Ensemble at 0x7fc27f9fbc40>
The ensemble has an object table, capturing the information about the global properties of each lightcurve, while the actual observations are stored in the source table. In this case, our object table is empty, as no such information is provided. More information is available in the Working with the TAPE Ensemble object tutorial.
[7]:
ens.object.head(5)
[7]:
| id_ens |
|---|
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
[8]:
ens.source.head(5)
[8]:
| t_ens | y_ens | yerr_ens | filter_ens | |
|---|---|---|---|---|
| id_ens | ||||
| 0 | 106.955696 | 0.087938 | 0.024990 | r |
| 0 | 118.271827 | 0.303914 | 0.035574 | r |
| 0 | 123.747375 | 0.219127 | 0.030438 | r |
| 0 | 124.477448 | 0.184467 | 0.028648 | r |
| 0 | 125.937594 | 0.196859 | 0.029263 | r |
To do more complex structure function calculations, we provide a powerful interface where users can extensively customize their calculations. This is done by instantiating StructureFunctionArgumentContainer and the specifying values for available options.
Below, we show an example where we 1. Specify that we want the calculation to be `combined’, i.e., gather all of the data-pairs from different lightcurves together before calculating excess variance 2. Specify the number of data pairs in a single time-bin (100000). 3. Specify that we wish to estimate error. This is done by bootstrapping a sample of data pairs and estimating the 16th and 84th quantiles of the distribution. 4. Specify how many bootstrapping resamples to do (100). This is also roughly the factor by which the calculation will slow down - because resampling takes the most computation time here. On the other hand, the estimate of the errors will be more accurate with more resampling.
[9]:
arg_container = StructureFunctionArgumentContainer()
arg_container.combine = True
arg_container.bin_count_target = 100000
arg_container.estimate_err = True
arg_container.calculation_repetitions = 100
res_sf2 = ens.sf2(argument_container=arg_container)
# We can also operate on a single lightcurve, without going via ensemble,
# but with full amount of options going via argument container
j = 7 # random lightcurve
arg_container.combine = False # do not combine - only one lightcurve
# only one lightcurve instead of 100 - specify 100 smaller count to get similar time-bin size as in
# the full ensemble case
arg_container.bin_count_target = 1000
res_one = tape.analysis.calc_sf2(t[j], y[j], err[j], argument_container=arg_container)
# create error array here
error_array = np.zeros(len(y[j]))
[10]:
# To compare with empirical results we create theoretical structure function of the underlying model
t_th = np.arange(0, 10000, 1)
SF_th = (amp**2 * 2) * (1 - np.exp(-t_th / tau))
[11]:
res_sf2.head(5)
[11]:
| lc_id | band | dt | sf2 | 1_sigma | |
|---|---|---|---|---|---|
| 0 | combined | r | 32.951168 | 0.020664 | 0.000115 |
| 1 | combined | r | 101.710785 | 0.052294 | 0.000316 |
| 2 | combined | r | 208.759245 | 0.073637 | 0.000519 |
| 3 | combined | r | 302.067503 | 0.077625 | 0.000293 |
| 4 | combined | r | 385.740042 | 0.078841 | 0.000311 |
[12]:
res_one.head(5)
[12]:
| lc_id | band | dt | sf2 | 1_sigma | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 31.819661 | 0.016079 | 0.000800 |
| 1 | 0 | 0 | 118.186754 | 0.044140 | 0.002138 |
| 2 | 0 | 0 | 292.167292 | 0.052344 | 0.002413 |
| 3 | 0 | 0 | 361.197217 | 0.105811 | 0.004161 |
| 4 | 0 | 0 | 432.371040 | 0.133225 | 0.004744 |
[13]:
plt.figure()
plt.errorbar(
res_sf2["dt"],
res_sf2["sf2"],
yerr=res_sf2["1_sigma"],
marker=".",
capsize=2,
label="ensemble result",
color="red",
)
plt.errorbar(
res_one["dt"],
res_one["sf2"],
yerr=res_one["1_sigma"],
marker=".",
capsize=2,
label="single lightcurve result",
color="orange",
)
plt.plot(t_th, SF_th, marker="", label="theoretical result", color="black", lw=2)
plt.yscale("log")
plt.xscale("log")
plt.title("Ensemble and single structure function")
plt.xlabel("Time [time unit]")
plt.ylabel("SF^2 [magnitude unit^2]")
plt.ylim(10 ** (-2), 10 ** (-0.4))
plt.xlim(10 ** (1), 10 ** (3.8))
plt.legend()
plt.show()
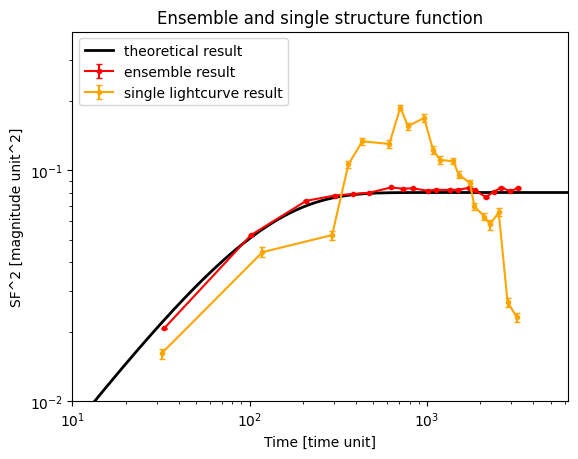
Let us discuss what is the meaning of these error bars. They are calculated from bootstrapping the sample, and as such, they should capture the inherent uncertainty of the stochastic process. In order to be less sensitive to the outliers, they are calculated by comparing the 84th and 16th quantiles of the distribution of generated structure function results. The code below illustrates the procedure.
[14]:
# For the same lightcurve as above, let us resample it 100 times and put the results in separate array
arg_container.estimate_err = False
res_resample_arr = np.zeros((100, 20))
for i in range(100):
resample_arr = np.sort(np.random.choice(np.arange(0, 200), size=len(y[j]), replace=True))
res_resample = tape.analysis.calc_sf2(
t[j][resample_arr], y[j][resample_arr], err[j][resample_arr], argument_container=arg_container
)
res_resample_arr[i] = res_resample["sf2"].values
[15]:
# Show all of the 100 results in faint yellow
plt.plot(res_one["dt"], res_resample_arr.transpose(), alpha=0.3, color="yellow")
plt.errorbar(
res_one["dt"],
res_one["sf2"],
yerr=res_one["1_sigma"],
marker=".",
capsize=2,
label="single lightcurve result",
color="orange",
)
plt.plot(t_th, SF_th, marker="", label="theoretical result", color="black", lw=2)
plt.yscale("log")
plt.xscale("log")
plt.title("Ensemble and single structure function")
plt.xlabel("Time [time unit]")
plt.ylabel("SF^2 [magnitude unit^2]")
plt.ylim(10 ** (-2), 10 ** (-0.4))
plt.xlim(10 ** (1), 10 ** (3.8))
plt.legend()
plt.show()

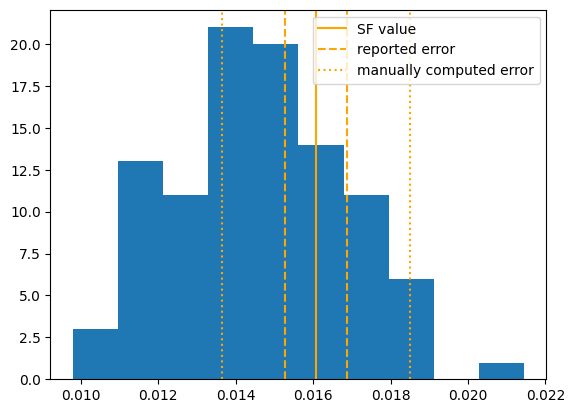
Let us look at the distribution of results in the shortest time bin. With the orange line, we denote the result from the non-resampled lightcurve, and we compare the error reported from the calculation and the error computed ``manually’’ above.
We see quite a difference between the errors we computed manually and from the code! This problem is captured in: lincc-frameworks/tape#198
[16]:
plt.hist(res_resample_arr.transpose()[0])
err_manual = (
np.quantile(res_resample_arr.transpose()[0], 0.84) - np.quantile(res_resample_arr.transpose()[0], 0.16)
) / 2
plt.axvline(res_one["sf2"][0], color="orange", label="SF value")
plt.axvline(res_one["sf2"][0] + res_one["1_sigma"][0], color="orange", ls="--", label="reported error")
plt.axvline(res_one["sf2"][0] - res_one["1_sigma"][0], color="orange", ls="--")
plt.axvline(res_one["sf2"][0] + err_manual, color="orange", ls=":", label="manually computed error")
plt.axvline(res_one["sf2"][0] - err_manual, color="orange", ls=":")
plt.legend()
[16]:
<matplotlib.legend.Legend at 0x7fc274f61e70>
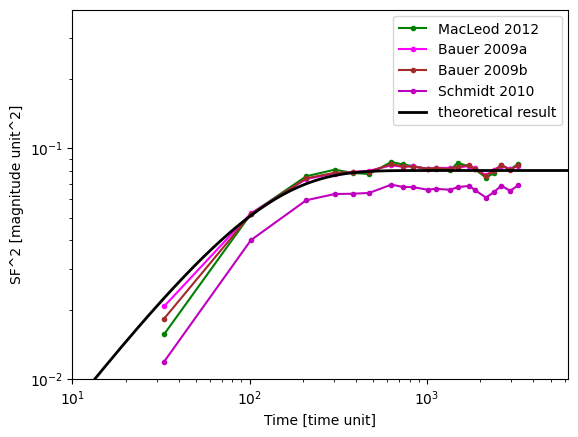
Structure function methods#
Numerous different definitions exist for structure calculation. This is because the original formula is very sensitive to outliers (in a quadratic fashion), so a couple of outliers can completely distort the results. Therefore, multiple different approaches exist which produce the same result as the original equation under certain assumptions, but are less sensitive to problems in the data.
To access these methods, specify the sf_method argument, as shown below.
[17]:
# This takes at the moment 3 minutes, 25 seconds
arg_container = tape.analysis.structure_function.StructureFunctionArgumentContainer()
arg_container.sf_method = "macleod_2012"
arg_container.combine = True
arg_container.bin_count_target = 100000
arg_container.calculation_repetitions = 1
res_macleod = ens.sf2(argument_container=arg_container)
arg_container.sf_method = "bauer_2009a"
res_bauer_a = ens.sf2(argument_container=arg_container)
arg_container.sf_method = "bauer_2009b"
res_bauer_b = ens.sf2(argument_container=arg_container)
arg_container.sf_method = "schmidt_2010"
res_schmidt = ens.sf2(argument_container=arg_container)
[18]:
# plt.plot(res_basic['dt'], res_basic['sf2'], 'b', label='Basic', lw = 3, marker = 'o')
plt.plot(res_macleod["dt"], res_macleod["sf2"], "g", marker=".", label="MacLeod 2012")
plt.plot(res_bauer_a["dt"], res_bauer_a["sf2"], "magenta", marker=".", label="Bauer 2009a")
plt.plot(res_bauer_b["dt"], res_bauer_b["sf2"], "brown", marker=".", label="Bauer 2009b")
plt.plot(res_schmidt["dt"], res_schmidt["sf2"], "m", marker=".", label="Schmidt 2010")
plt.plot(t_th, SF_th, marker="", label="theoretical result", color="black", lw=2)
plt.legend()
plt.yscale("log")
plt.xscale("log")
plt.xlabel("Time [time unit]")
plt.ylabel("SF^2 [magnitude unit^2]")
plt.ylim(10 ** (-2), 10 ** (-0.4))
plt.xlim(10 ** (1), 10 ** (3.8))
plt.legend()
[18]:
<matplotlib.legend.Legend at 0x7fc274fa1750>